Large language models (LLMs) have shown remarkable success, but aligning them with human preferences remains a core challenge. As individuals have their own, multi-dimensional preferences, recent studies have explored multi-dimensional personalization, which aims to enable models to generate responses personalized to explicit preferences. However, human preferences are often implicit and thus difficult to articulate, limiting the direct application of this approach. To bridge this gap, we introduce a comparison-based active preference learning framework to capture implicit user preferences. Building on Bayesian inference, our work introduces a modified posterior update procedure to mitigate estimation bias and potential noise in comparisons. Also, inspired by generalized binary search, we employ an active query selection strategy to minimize the number of required comparisons by a user. Through theoretical analysis and experiments on language generation tasks, we demonstrate feedback efficiency and effectiveness of our framework in personalizing model responses.
Quick summary
- Comparison-based preference learning
- Robust to estimation bias and feedback noise
- Efficient elicitation
Multi-dimensional personalization
Real-world user preferences are multi-dimensional, encompassing a range of distinct, often intertwined aspects such as tone, style, content focus, and safety. Given that users often prioritize these aspects differently, a single, generic model struggles to meet distinct individual needs. This underscores the critical role of multi-dimensional personalization in generating responses that precisely match individual user preferences.
This illustrates 5-dimensional scores of two model responses for a prompt. Based on how a user prioritizes these 5 aspects, either response can be chosen.
Infer hidden user preferences through comparisons
User preferences are often implicit, making them difficult for users to directly articulate. We address this by inferring underlying multi-dimensional preferences through comparative feedback, where users can reveal their true leanings by choosing between options (pairs of responses).
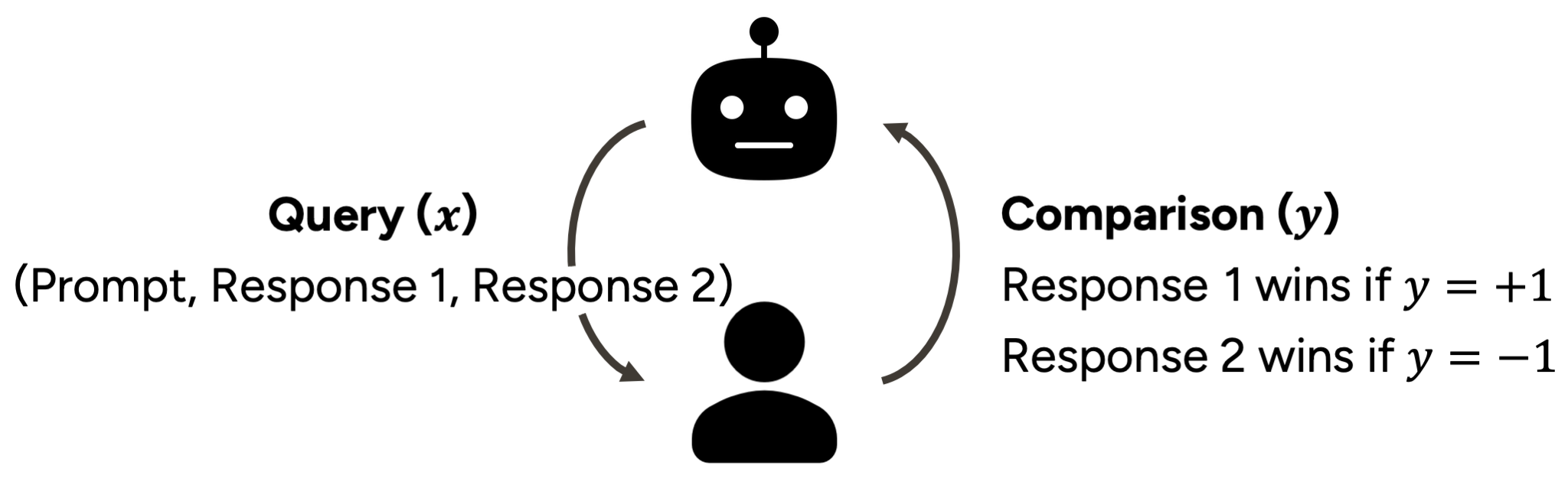
The agent selects a query (i.e., "which one do you prefer for this prompt, response 1 or response 2?") and then the user provides as feedback (i.e., "I prefer response #!"). This query-feedback cycle is repeated until the agent identifies the user's preferences.
Robust preference learning with bias and noise mitigation
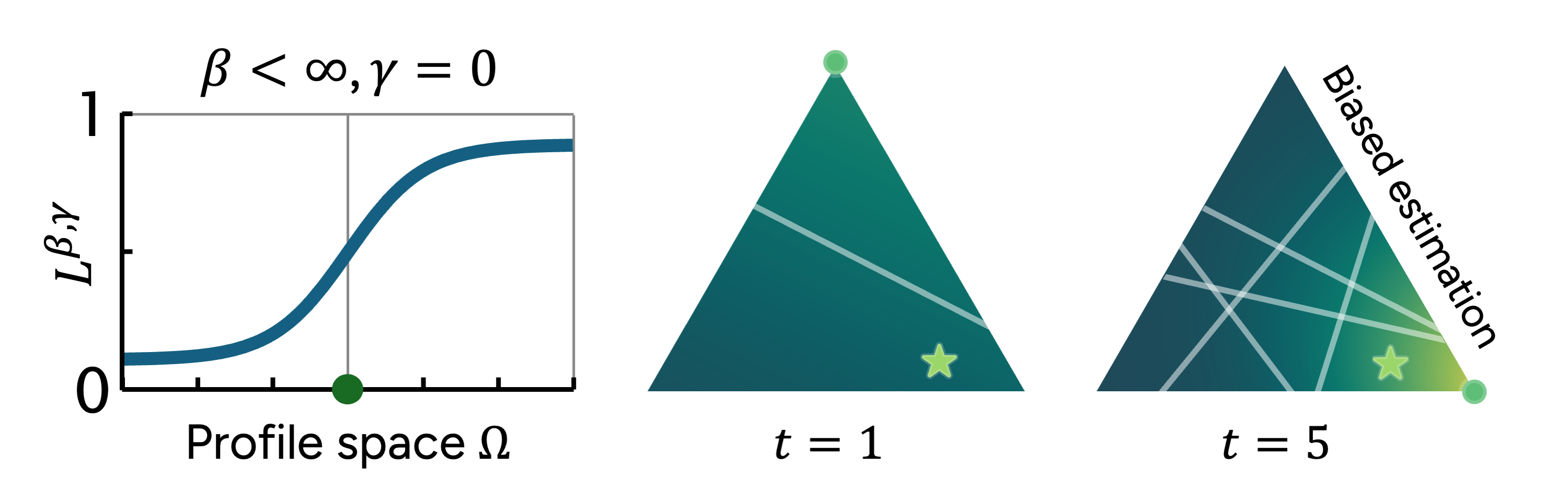
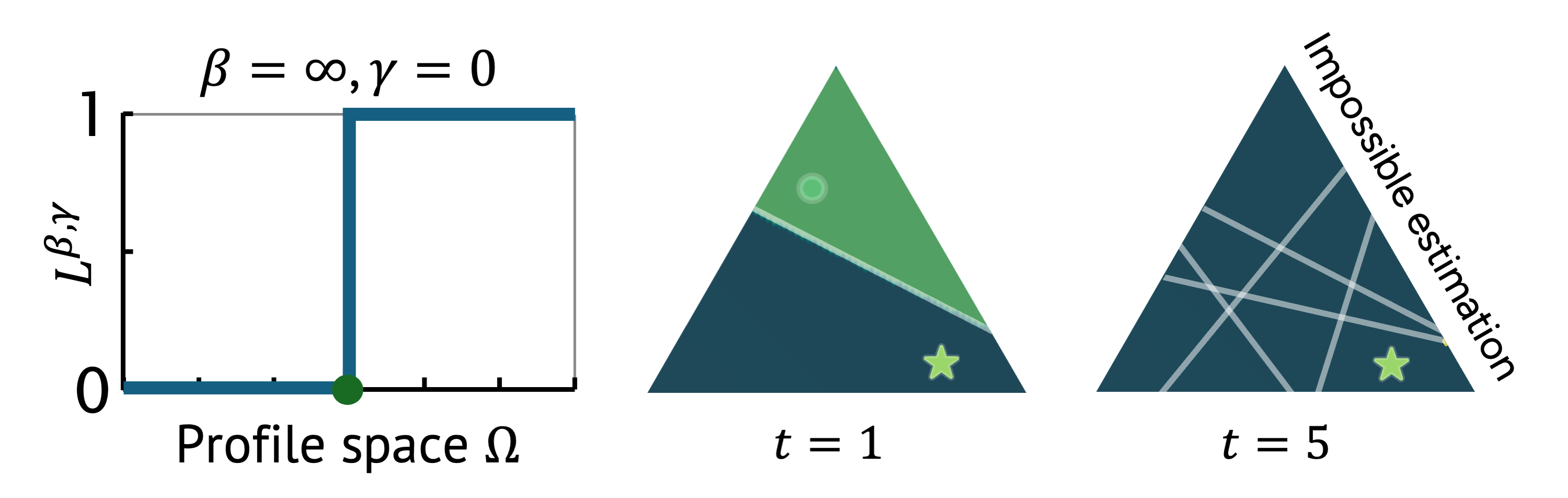
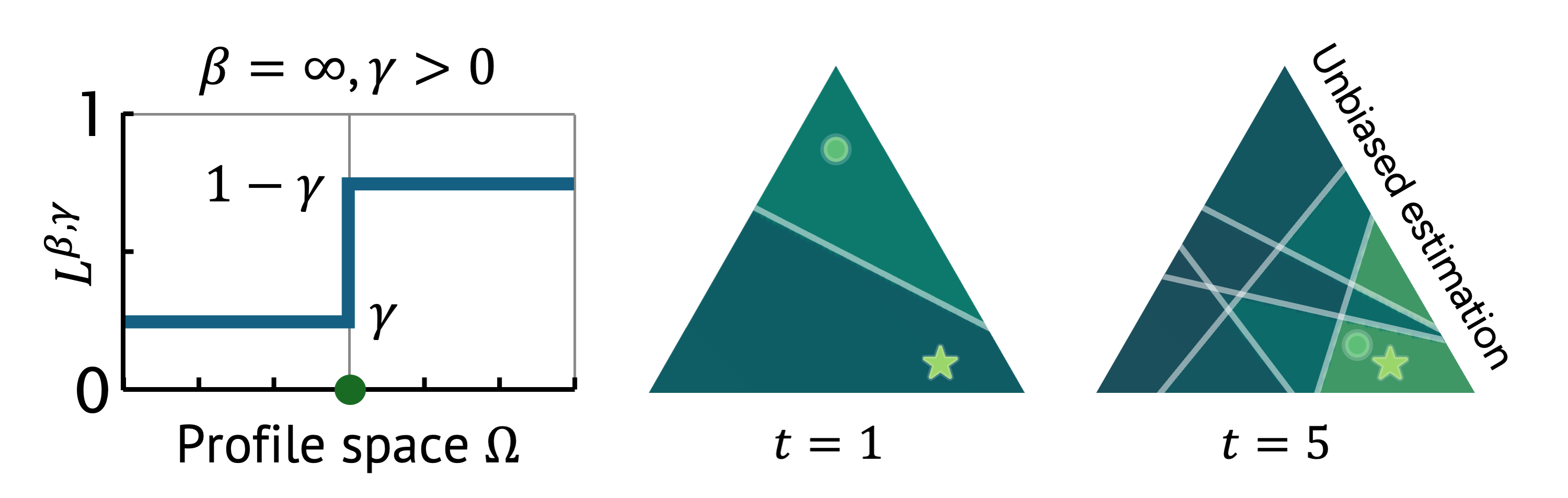
We found an issue of estimation bias in existing preference learning approaches, where estimation errors may not converge to zero. Recognizing this, and the pervasive issue of inherent noise in user feedback, we propose a modified posterior update. This design allows us to avoid potential biases in preference estimation and to control how skeptical we are towards provided user feedback, leading to more reliable and robust preference learning.
Upon receiving user feedback for a query , we refine our understanding of the user's preferences, represented by the belief distribution . This update is governed by , where the likelihood function is defined as
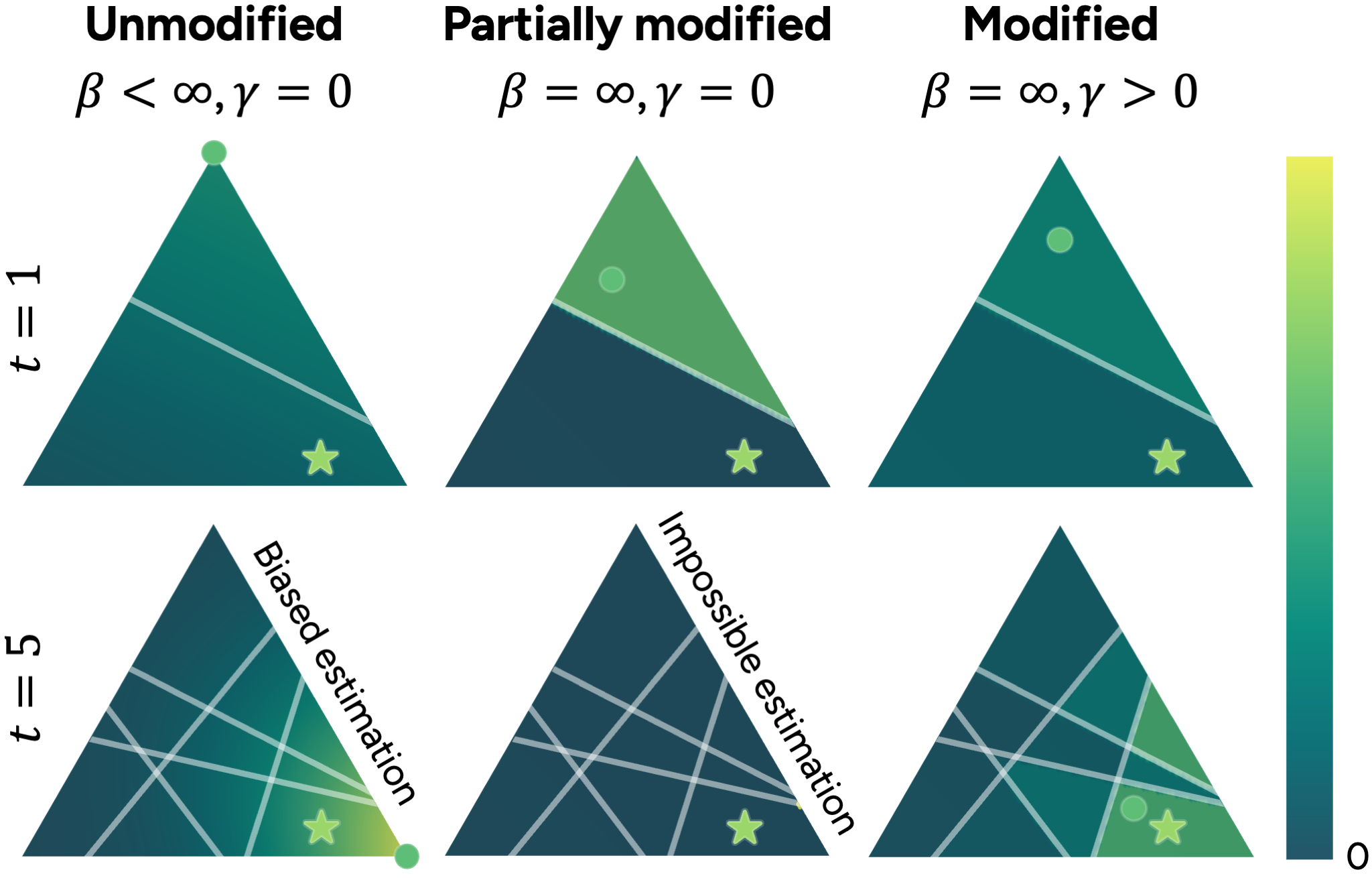
Impact of likelihood functions on preference estimation.
See below for more illustrative explanation.
Minimize user effort with efficient query selection
To obtain maximum information while minimizing user interaction (comparative queries), we utilize an active query selection strategy inspired by the principle of generalized binary search. This dramatically reduces the number of required questions and maximizes learning efficiency.

Visualization of modified posterior updates. This shows the belief distribution at the first five rounds. The true preference and the estimator are marked by the star and circle, respectively. Each chosen query is represented by a solid line. As shown, each query down-weights roughly half of the previous distribution.
Experiments
Robust and efficient preference learning
Unmodified updates converge not at all or slowly. In contrast, our modified update ensures convergence. When combined with our volume-halving queries, we achieve the fastest and most stable convergence.
More than about 10% of the feedback are noise.
More than about 10% of the feedback are noise.
Under ideal conditions—no noise in the feedback—we can see the same resultant tendency, but with even more pronounced performance gap.
No feedback is noise.
No feedback is noise.